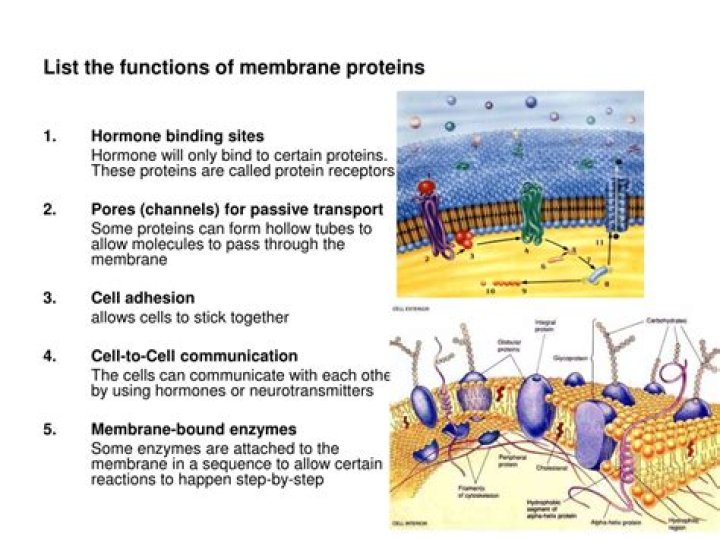
Why UTF-8 is used in HTML

Rachel Hickman
Published Feb 16, 2026
Why use UTF-8? An HTML page can only be in one encoding. You cannot encode different parts of a document in different encodings. A Unicode-based encoding such as UTF-8 can support many languages and can accommodate pages and forms in any mixture of those languages.
What encoding should I use for HTML?
You should always use the UTF-8 character encoding.
What is the difference between UTF-16 and UTF-8?
1. UTF-8 uses one byte at the minimum in encoding the characters while UTF-16 uses minimum two bytes. … In short, UTF-8 is variable length encoding and takes 1 to 4 bytes, depending upon code point. UTF-16 is also variable length character encoding but either takes 2 or 4 bytes.
What is UTF-16 encoding?
UTF-16 is an encoding of Unicode in which each character is composed of either one or two 16-bit elements. Unicode was originally designed as a pure 16-bit encoding, aimed at representing all modern scripts. … UTF-16 allows access to about 60 000 characters as single Unicode 16-bit units.Is UTF 8 and Unicode the same?
UTF-8 is a method for encoding Unicode characters using 8-bit sequences. Unicode is a standard for representing a great variety of characters from many languages.
Why HTML encoding is required?
HTML encoding ensures that text will be correctly displayed in the browser, not interpreted by the browser as HTML. For example, if a text string contains a less than sign (<) or greater than sign (>), the browser would interpret these characters as an opening or closing bracket of an HTML tag.
What is encoding UTF 8 in Python?
UTF-8 is one of the most commonly used encodings, and Python often defaults to using it. UTF stands for “Unicode Transformation Format”, and the ‘8’ means that 8-bit values are used in the encoding. … UTF-8 uses the following rules: If the code point is < 128, it’s represented by the corresponding byte value.
What is UTF-16 Le bom?
UTF-16LE is a variation of UTF-16. UTF-16LE: A character encoding that maps code points of Unicode character set to a sequence of 2 bytes (16 bits). UTF-16LE stands for Unicode Transformation Format – 16-bit Little Endian.What is UCS 2 LE BOM encoding?
UCS-2 is a character encoding standard in which characters are represented by a fixed-length 16 bits (2 bytes). It is used as a fallback on many GSM networks when a message cannot be encoded using GSM-7 or when a language requires more than 128 characters to be rendered.
What is UTF with BOM?21. 864. The UTF-8 BOM is a sequence of bytes at the start of a text stream ( 0xEF, 0xBB, 0xBF ) that allows the reader to more reliably guess a file as being encoded in UTF-8. Normally, the BOM is used to signal the endianness of an encoding, but since endianness is irrelevant to UTF-8, the BOM is unnecessary.
Article first time published onWhat are UTF-8 and UTF-32 encoding schemes?
UTF-8 is a variable length encoding scheme that uses different number of bytes to represent different characters whereas UTF-32 is a fixed length encoding scheme that uses exactly 4 bytes to represent all Unicode code points. UTF-8 is the more popular encoding scheme.
What is difference between ASCII and Unicode?
The difference between Unicode and ASCII is that Unicode is the IT standard that represents letters of English, Arabic, Greek (and many more languages), mathematical symbols, historical scripts, etc whereas ASCII is limited to few characters such as uppercase and lowercase letters, symbols, and digits(0-9).
What is difference between UTF-8 and ASCII?
UTF-8 encodes Unicode characters into a sequence of 8-bit bytes. … By comparison, ASCII (American Standard Code for Information Interchange) includes 128 character codes. Eight-bit extensions of ASCII, (such as the commonly used Windows-ANSI codepage 1252 or ISO 8859-1 “Latin -1”) contain a maximum of 256 characters.
What is Python default encoding?
The default encoding in Python-2 is ASCII, don’t change it just to run your code. For python portability, every string in Python(3+) is now Unicode.
Is UTF-16 compatible with ASCII?
Compatibility issues UTF-16 and UTF-32 are incompatible with ASCII files, and thus require Unicode-aware programs to display, print and manipulate them, even if the file is known to contain only characters in the ASCII subset.
Is Python a UTF-8 string?
In Python, Strings are by default in utf-8 format which means each alphabet corresponds to a unique code point.
What does B mean in Python?
The b” notation is used to specify a bytes string in Python. Compared to the regular strings, which have ASCII characters, the bytes string is an array of byte variables where each hexadecimal element has a value between 0 and 255.
What Unicode means?
Unicode is a universal character encoding standard that assigns a code to every character and symbol in every language in the world. Since no other encoding standard supports all languages, Unicode is the only encoding standard that ensures that you can retrieve or combine data using any combination of languages.
What does ASCII mean in Python?
Python ascii() Method. ASCII stands for American Standard Code for Information Interchange. It is a character encoding standard that uses numbers from 0 to 127 to represent English characters.
What is HTML encoding C#?
Part A The HtmlEncode method is designed to receive a string that contains HTML markup characters such as > and <. Part B HtmlDecode, meanwhile, is designed to reverse those changes. It changes encoded characters back to actual HTML. C# program that uses HtmlEncode and HtmlDecode.
What is HTML encoded?
HTML Encoding means to convert the document that contains special characters outside the range of normal seven-bit ASCII into a standard form. … HTML encoding makes sure that text is displayed correctly in the browser and not interpreted by the browser as HTML.
Does HTML encoding prevent XSS?
No. Putting aside the subject of allowing some tags (not really the point of the question), HtmlEncode simply does NOT cover all XSS attacks.
What UCS 4?
UCS-4 stands for “Universal Character Set coded in 4 octets.” It is now treated simply as a synonym for UTF-32, and is considered the canonical form for representation of characters in ISO 10646 (Universal Coded Character Set).
What is the difference between UCS-2 and UTF-16?
UCS-2 is a fixed width encoding that uses two bytes for each character; meaning, it can represent up to a total of 216 characters or slightly over 65 thousand. On the other hand, UTF-16 is a variable width encoding scheme that uses a minimum of 2 bytes and a maximum of 4 bytes for each character.
What is GSM 7 bit encoding?
GSM-7 is a character encoding standard which packs the most commonly used letters and symbols in many languages into 7 bits each for usage on GSM networks. As SMS messages are transmitted 140 8-bit octets at a time, GSM-7 encoded SMS messages can carry up to 160 characters.
What are ascii and Iscii Why are these used?
ASCII code is mostly used to represent the characters of English language, standard keyboard characters as well as control characters like Carriage Return and Form Feed. ISCII stands for Indian Standard Code for Information Interchange. It uses a 8-bit code and it can represent 256 characters.
What is UTF 32 encoding?
UTF-32 (32-bit Unicode Transformation Format) is a fixed-length encoding used to encode Unicode code points that uses exactly 32 bits (four bytes) per code point (but a number of leading bits must be zero as there are far fewer than 232 Unicode code points, needing actually only 21 bits).
Should I use UTF-8 or UTF-16?
Depends on the language of your data. If your data is mostly in western languages and you want to reduce the amount of storage needed, go with UTF-8 as for those languages it will take about half the storage of UTF-16.
What is feff hex character?
Our friend FEFF means different things, but it’s basically a signal for a program on how to read the text. It can be UTF-8 (more common), UTF-16 , or even UTF-32 . FEFF itself is for UTF-16 — in UTF-8 it is more commonly known as 0xEF,0xBB, or 0xBF .
What is byte order mark used for?
The byte-order mark indicates which order is used, so that applications can immediately decode the content. In the UTF-8 encoding, the presence of the BOM is not essential because, unlike the UTF-16 encodings, there is no alternative sequence of bytes in a character.
What is ANSI encoding?
ANSI encoding is a slightly generic term used to refer to the standard code page on a system, usually Windows. It is more properly referred to as Windows-1252 on Western/U.S. systems. (It can represent certain other Windows code pages on other systems.)