What is product clustering

Sophia Edwards
Published Mar 20, 2026
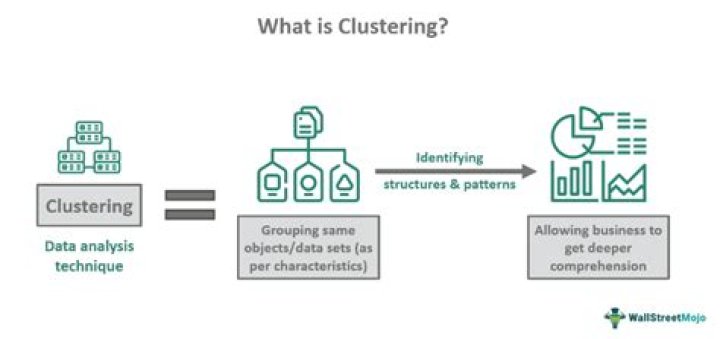
Product Clustering¶ The Product Clustering model is an unsupervised learning model that groups customers based on the type of products they buy or do not buy. In other words, this model groups customers based on their buying behavior of specific products or categories.
What does clustering mean in marketing?
In Predictive Marketing the term ‘clustering’ gets thrown around quite a lot. … Segmenting is the process of putting customers into groups based on similarities, and clustering is the process of finding similarities in customers so that they can be grouped, and therefore segmented.
What is clustering in simple terms?
Clustering is the task of dividing the population or data points into a number of groups such that data points in the same groups are more similar to other data points in the same group than those in other groups. In simple words, the aim is to segregate groups with similar traits and assign them into clusters.
What is product cluster analysis?
In the context of customer segmentation, cluster analysis is the use of a mathematical model to discover groups of similar customers based on finding the smallest variations among customers within each group. These homogeneous groups are known as “customer archetypes” or “personas”.What is the clustering process?
Clustering is the process of making a group of abstract objects into classes of similar objects. Points to Remember. A cluster of data objects can be treated as one group. While doing cluster analysis, we first partition the set of data into groups based on data similarity and then assign the labels to the groups.
What is customer clustering?
Customer clustering or segmentation is the process of dividing an organisation’s customers into groups or ‘clusters’ that reflect similarity amongst customers in that particular group. … Compared to rule based segmentation, AI powered customer clustering finds closer affinity among customers within a cluster.
Why is a cluster important?
Clusters support innovation and growth. They start in many ways, but all offer knowledge sharing, partnership, infrastructure, a skills pool and career opportunities. … For big business – being present in a relevant cluster is a great way to sense the direction of innovation and to find new partners.
What are different types of clustering?
- Connectivity-based Clustering (Hierarchical clustering)
- Centroids-based Clustering (Partitioning methods)
- Distribution-based Clustering.
- Density-based Clustering (Model-based methods)
- Fuzzy Clustering.
- Constraint-based (Supervised Clustering)
Where is clustering used?
Clustering technique is used in various applications such as market research and customer segmentation, biological data and medical imaging, search result clustering, recommendation engine, pattern recognition, social network analysis, image processing, etc.
What is the difference between clustering and classification?Although both techniques have certain similarities, the difference lies in the fact that classification uses predefined classes in which objects are assigned, while clustering identifies similarities between objects, which it groups according to those characteristics in common and which differentiate them from other …
Article first time published onHow many types of clustering are there?
Clustering itself can be categorized into two types viz. Hard Clustering and Soft Clustering.
Why choose K means clustering?
The K-means clustering algorithm is used to find groups which have not been explicitly labeled in the data. This can be used to confirm business assumptions about what types of groups exist or to identify unknown groups in complex data sets.
How clustering algorithms work?
Clustering is an Unsupervised Learning algorithm that groups data samples into k clusters. The algorithm yields the k clusters based on k averages of points (i.e. centroids) that roam around the data set trying to center themselves — one in the middle of each cluster.
What is good clustering?
A good clustering method will produce high quality clusters in which: the intra-class (that is, intra intra-cluster) similarity is high. the inter-class similarity is low. The quality of a clustering result also depends on both the similarity measure used by the method and its implementation.
What is partitioning in data mining?
This clustering method classifies the information into multiple groups based on the characteristics and similarity of the data. Its the data analysts to specify the number of clusters that has to be generated for the clustering methods.
What are the advantages and disadvantages of clustering?
The main advantage of a clustered solution is automatic recovery from failure, that is, recovery without user intervention. Disadvantages of clustering are complexity and inability to recover from database corruption.
What are the benefits of industrial clusters?
- Increased Productivity. The specialized inputs, synergies, and increased access to information/public goods that accompany cluster manufacturing all boost productivity of plants.
- Specialized Workers. …
- Retrieving Investors. …
- Rapid Innovation. …
- More Effective Business Formations. …
- Not without fault.
What are the advantages of industrial clusters?
Industrial clusters allow the companies to be more productive and more innovative. The Industrial clusters develop unique knowledge and skills difficult to be replicated.
How do businesses use clustering?
Clustering can help businesses to manage their data better – image segmentation, grouping web pages, market segmentation and information retrieval are four examples. For retail businesses, data clustering helps with customer shopping behavior, sales campaigns and customer retention.
Is image segmenting clustering?
Image segmentation is the classification of an image into different groups. Many researches have been done in the area of image segmentation using clustering. … Subtractive clustering method is data clustering method where it generates the centroid based on the potential value of the data points.
What is clustered preference?
Clustered Preferences: The clustered preferences, refer to the natural segments that get created due to the shared preferences of a group of customers.
What is clustering in Python?
Be sure to take a look at our Unsupervised Learning in Python course. Clustering is the task of grouping together a set of objects in a way that objects in the same cluster are more similar to each other than to objects in other clusters. … A centroid is a data point (imaginary or real) at the center of a cluster.
Is clustering an algorithm?
Clustering is a Machine Learning technique that involves the grouping of data points. Given a set of data points, we can use a clustering algorithm to classify each data point into a specific group.
What is Birch in data mining?
BIRCH (balanced iterative reducing and clustering using hierarchies) is an unsupervised data mining algorithm used to perform hierarchical clustering over particularly large data-sets. … In most cases, BIRCH only requires a single scan of the database.
Which is not type of clustering?
option3: K – nearest neighbor method is used for regression & classification but not for clustering. option4: Agglomerative method uses the bottom-up approach in which each cluster can further divide into sub-clusters i.e. it builds a hierarchy of clusters.
What is the difference between clustering and prediction?
Predictive models are sometimes called learning with a teacher, whereas in clustering you’re left completely alone. Predictive models split data into training and testing subsample which is used for verifying computed model. Predictive (or regression) model typically assign weights to each attribute.
What is regression and clustering?
Regression: It predicts continuous values and their output. Regression analysis is the statistical model that is used to predict the numeric data instead of labels. … Clustering: Clustering is quite literally the clustering or grouping up of data according to the similarity of data points and data patterns.
What is the difference between clustering and regression?
Regression and Classification are types of supervised learning algorithms while Clustering is a type of unsupervised algorithm. When the output variable is continuous, then it is a regression problem whereas when it contains discrete values, it is a classification problem.
What is called cluster?
A cluster is a small group of people or things. When you and your friends huddle awkwardly around the snack table at a party, whispering and trying to muster enough nerve to hit the dance floor, you’ve formed a cluster. Cluster comes to us from the Old English word clyster, meaning bunch.
What is Weka tool?
Weka is a collection of machine learning algorithms for data mining tasks. The algorithms can either be applied directly to a dataset or called from your own Java code. Weka contains tools for data pre-processing, classification, regression, clustering, association rules, and visualization.
What is DWM classification?
Classification is the problem of identifying to which of a set of categories (subpopulations), a new observation belongs to, on the basis of a training set of data containing observations and whose categories membership is known.