What is metadata in Hadoop

Emma Valentine
Published Mar 19, 2026
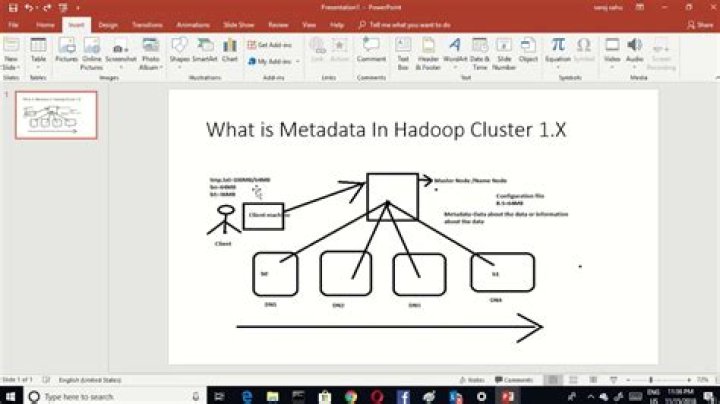
Metadata is the data about the data. Metadata is stored in namenode where it stores data about the data present in datanode like location about the data and their replicas.
What is metadata in hive?
What is Hive Metastore? Metastore is the central repository of Apache Hive metadata. It stores metadata for Hive tables (like their schema and location) and partitions in a relational database. It provides client access to this information by using metastore service API.
Who maintains metadata in Hadoop?
Each DataNode keeps a small amount of metadata allowing it to identify the cluster it participates in. If this metadata is lost, then the DataNode cannot participate in an HDFS instance and the data blocks it stores cannot be reached.
What is called metadata?
Data that provide information about other data. Metadata summarizes basic information about data, making finding & working with particular instances of data easier. Metadata can be created manually to be more accurate, or automatically and contain more basic information.How does HDFS manage metadata?
Each computer has its own file system and information about an HDFS file—the metadata—is managed by the NameNode and persistent information is stored in the NameNode’s host file system. The information contained in an HDFS file is managed by a DataNode and stored on the DataNode’s host computer file system.
Where is data stored in Hive?
The data loaded in the hive database is stored at the HDFS path – /user/hive/warehouse. If the location is not specified, by default all metadata gets stored in this path.
Where is metadata stored in Hive?
Metastore is a repository for Hive metadata. It stores metadata for Hive tables, and you can think of this as your schema. This is located on the Apache Derby DB. Hive uses the MapReduce framework to process queries.
What is metadata give an example?
Metadata is data about data. … A simple example of metadata for a document might include a collection of information like the author, file size, the date the document was created, and keywords to describe the document. Metadata for a music file might include the artist’s name, the album, and the year it was released.What is metadata Geeksforgeeks?
Metadata is simply defined as data about data. It means it is a description and context of the data. It helps to organize, find and understand data.
What is metadata and its types?There are THREE (3) different types of metadata: descriptive, structural, and administrative. Descriptive: describes a resource for purposes such as discovery and identification. It can include elements such as title, abstract, author, and keywords.
Article first time published onWhat is MapReduce in big data?
MapReduce is a programming model for processing large data sets with a parallel , distributed algorithm on a cluster (source: Wikipedia). Map Reduce when coupled with HDFS can be used to handle big data. … Semantically, the map and shuffle phases distribute the data, and the reduce phase performs the computation.
What is name node?
The NameNode is the centerpiece of an HDFS file system. It keeps the directory tree of all files in the file system, and tracks where across the cluster the file data is kept. … The NameNode responds the successful requests by returning a list of relevant DataNode servers where the data lives.
Why MapReduce is used in Hadoop?
MapReduce is a Hadoop framework used for writing applications that can process vast amounts of data on large clusters. It can also be called a programming model in which we can process large datasets across computer clusters. This application allows data to be stored in a distributed form.
What is namespace in Hadoop?
In Hadoop we refer to a Namespace as a file or directory which is handled by the Name Node. … Namespace act as a container where file name grouping and metadata which also contains things like the owners of files, permission bits, block location, size etc will be present.
What is NameNode and DataNode in HDFS?
Key Points. The main difference between NameNode and DataNode in Hadoop is that the NameNode is the master node in Hadoop Distributed File System (HDFS) that manages the file system metadata while the DataNode is a slave node in Hadoop distributed file system that stores the actual data as instructed by the NameNode.
Which node stores metadata in Hadoop?
Metadata is the data about the data. Metadata is stored in namenode where it stores data about the data present in datanode like location about the data and their replicas. NameNode stores the Metadata, this consists of fsimage and editlog.
How do I find metadata in Hive?
When using Hive, you access metadata about schemas and tables by executing statements written in HiveQL (Hive’s version of SQL) such as SHOW TABLES . When using the HCatalog Connector, you can get metadata about the tables in the Hive database through several Vertica system tables.
What is Metastore service?
Hive metastore (HMS) is a service that stores metadata related to Apache Hive and other services, in a backend RDBMS, such as MySQL or PostgreSQL. A separate RDBMS supports the security service, Ranger for example. … All connections are routed to a single RDBMS service at any given time.
How is data stored in Hive?
Hive data are stored in one of Hadoop compatible filesystem: S3, HDFS or other compatible filesystem. Hive metadata are stored in RDBMS like MySQL, see supported RDBMS. The location of Hive tables data in S3 or HDFS can be specified for both managed and external tables.
Which query language is used in Hive?
Hive queries are written in HiveQL, which is a query language similar to SQL. Hive allows you to project structure on largely unstructured data. After you define the structure, you can use HiveQL to query the data without knowledge of Java or MapReduce.
What is partitioning and bucketing in Hive?
Hive Partition is a way to organize large tables into smaller logical tables based on values of columns; one logical table (partition) for each distinct value. … Hive Bucketing a.k.a (Clustering) is a technique to split the data into more manageable files, (By specifying the number of buckets to create).
Why Hive is data warehouse?
Hive is a data warehouse infrastructure tool to process structured data in Hadoop. It resides on top of Hadoop to summarise Big Data and makes querying and analyzing easy. … It stores schema in a database and processes data into HDFS which is why its named as data warehouse tool.
What is the example of data?
Data is defined as facts or figures, or information that’s stored in or used by a computer. An example of data is information collected for a research paper. An example of data is an email. From the Latin datum, meaning what is given.
What is difference between metadata and data dictionary?
Metadata describes about data. It is ‘data about data’. … Data dictionary is a file which consists of the basic definitions of a database. It contains the list of files that are available in the database, number of records in each file, and the information about the fields.
What is difference between metadata and schema?
Metadata is ‘data about data’. Whereas Schema is the structure/layout of the system. Real world example for Metadata: The extra information generated when you take a picture with your phone such as date, location, etc. Real world example for Schema: The layout of a website such us where is the main title, content, etc.
What is the role of metadata?
Metadata ensures that we will be able find data, use data, and preserve and re-use data in the future. Finding Data: Metadata makes it much easier to find relevant data. … Metadata also makes text documents easier to find because it explains exactly what the document is about.
What is a metadata table?
Metadata tables provide the data definitions for the source data that is being consumed by the operational server. These tables provide the basic information to associate the source data to the member data.
What is metadata in ETL?
Metadata In ETL. Data warehouse team (or) users can use metadata in a variety of situations to build, maintain and manage the system. The basic definition of metadata in the Data warehouse is, “it is data about data”. Metadata can hold all kinds of information about DW data like: Source for any extracted data.
What are the 3 types of metadata?
There are three main types of metadata: descriptive, administrative, and structural.
What are the five types of metadata?
- Descriptive metadata. Descriptive metadata is, in its most simplified version, an identification of specific data. …
- Structural metadata. …
- Preservation metadata. …
- Provenance metadata. …
- Use metadata. …
- Administrative metadata.
What is metadata in SEO?
Simply put, metadata is data about data. With Search engines, such as Google, do not “read” your content (data.) … To increase the chances of your content being located in response to a search engine request, add appropriate metadata, such as a search engine title, description, keywords, copyright and event dates.