What is — direct in sqoop

Rachel Hickman
Published Mar 16, 2026
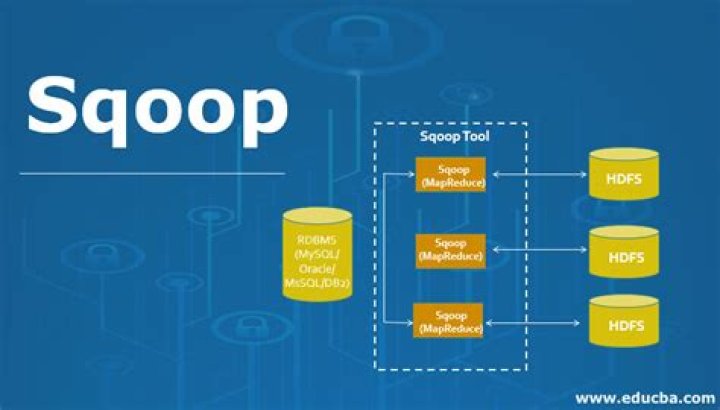
The –directive mode in scoop used for directly import multiple table or individual table into HIVE, HDFS, HBase. If we have a specific database connection directly apart from default database connection then –directive mode used.
Why are there 4 mappers in Sqoop?
Using more mappers will lead to a higher number of concurrent data transfer tasks, which can result in faster job completion. However, it will also increase the load on the database as Sqoop will execute more concurrent queries.
What is boundary query in Sqoop?
The boundary query is used for splitting the value according to id_no of the database table. To boundary query, we can take a minimum value and maximum value to split the value. To make split using boundary queries, we need to know all the values in the table.
What is incremental load in Sqoop?
The process to perform incremental data load in Sqoop is to synchronize the modified or updated data (often referred as delta data) from RDBMS to Hadoop. … 1)Mode (incremental) –The mode defines how Sqoop will determine what the new rows are. The mode can have value as Append or Last Modified.Why we use $conditions in Sqoop?
1 Answer. Sqoop performs highly efficient data transfers by inheriting Hadoop’s parallelism. To help Sqoop split your query into multiple chunks that can be transferred in parallel, you need to include the $CONDITIONS placeholder in the where clause of your query.
Why there is no reducer in sqoop?
There are no reducers in sqoop. Sqoop only uses mappers as it does parallel import and export. Whenever we write any query(even aggregation one such as count , sum) , these all queries run on RDBMS and the generated result is fetched by the mappers from RDBMS using select queries and it is loaded on hadoop parallely.
Can we control number of mappers in sqoop?
When importing data, Sqoop controls the number of mappers accessing RDBMS to avoid distributed denial of service attacks. 4 mappers can be used at a time by default, however, the value of this can be configured.
How can I improve my Sqoop performance?
Changing the number of mappers Typical Sqoop jobs launch four mappers by default. To optimise performance, increasing the map tasks (Parallel processes) to an integer value of 8 or 16 can show an increase in performance in some databases.What is split by in Sqoop?
–split-by : It is used to specify the column of the table used to generate splits for imports. This means that it specifies which column will be used to create the split while importing the data into your cluster. It can be used to enhance the import performance by achieving greater parallelism.
How you will handle the incremental data load in Sqoop?- Create a sample table and populate it with values. …
- Grant privileges on that table. …
- Create and execute a Sqoop job with incremental append option. …
- Observe metadata information in job. …
- Insert values in the source table.
- Execute the Sqoop job again and observe the output in HDFS.
What is free-form query in Sqoop?
Instead of using table import, use free-form query import. In this mode, Sqoop will allow you to specify any query for importing data. Instead of the parameter –table , use the parameter –query with the entire query for obtaining the data you would like to transfer.
How can we batch multiple insert statements together in Sqoop?
1. insert: insert mode will insert the new records from HDFS to RDBMS table. Sqoop exports each row at a time comparatively it is slow. We can optimized the speed of insertion by utilizing Sqoop JDBC interface batch (insert multiple rows together) insertion option.
What are the two different incremental modes of importing data into Sqoop?
Sqoop supports two types of incremental imports: append and lastmodified . You can use the –incremental argument to specify the type of incremental import to perform. You should specify append mode when importing a table where new rows are continually being added with increasing row id values.
What is the role of JDBC driver in sqoop?
What is the role of JDBC driver in a Sqoop set up? To connect to different relational databases sqoop needs a connector. Almost every DB vendor makes this connecter available as a JDBC driver which is specific to that DB. … Sqoop needs both JDBC and connector to connect to a database.
What is the use of mapper in sqoop?
The m or num-mappers argument defines the number of map tasks that Sqoop must use to import and export data in parallel. If you configure the m argument or num-mappers argument, you must also configure the split-by argument to specify the column based on which Sqoop must split the work units.
How does Mapper work in sqoop?
Nope, Sqoop is running a map-only job which each mapper (3 in my example above) running a query with a specific range to prevent any kind of overlap. The mapper then just drops the data in the target-dir HDFS directory with a file named part-m-00000 (well, the 2nd on ends with 00001 and the 3rd one ends with 00002).
What is the default number of reducers in Hadoop?
The default number of reducers for any job is 1. The number of reducers can be set in the job configuration.
How do you determine the number of mappers and reducers in hive?
It depends on how many cores and how much memory you have on each slave. Generally, one mapper should get 1 to 1.5 cores of processors. So if you have 15 cores then one can run 10 Mappers per Node. So if you have 100 data nodes in Hadoop Cluster then one can run 1000 Mappers in a Cluster.
What happens if sqoop fails in between a process?
If an export map task fails even after multiple retries, the entire job will fail. The reasons for task failures could include network connectivity issues, database integrity constraints, malformed records on HDFS , cluster capacity issues etc.
What is staging table in sqoop?
Data will be first loaded into staging table. … If there are no exceptions then data will be copied from staging table into the target table. If data in staging table is not cleaned up for any reason, we might have to use additional control argument –clear-staging-table .
What is check column in sqoop?
Here you should use an –incremental append with –check-column which specifies the column to be examined when determining which rows to import. sqoop import –connect jdbc:mysql://localhost:3306/ydb –table yloc –username root -P –check-column rank –incremental append –last-value 7.
What is the default mapper in sqoop?
when we don’t mention the number of mappers while transferring the data from RDBMS to HDFS file system sqoop will use default number of mapper 4.
What is fetch size in Sqoop?
Specifies the number of entries that Sqoop can import at a time.
What is the difference between Sqoop and hive?
What is the difference between Apache Sqoop and Hive? I know that sqoop is used to import/export data from RDBMS to HDFS and Hive is a SQL layer abstraction on top of Hadoop.
How fast is Sqoop?
It depends upon number of mappers assigned for that job. So for example , if standalone(single) process taking 4 minutes to transfer the data, Sqoop with 4 mappers will take less than 1 min.
What are the different Hadoop configuration files?
- Read-only default configuration – src/core/core-default. xml, src/hdfs/hdfs-default. xml and src/mapred/mapred-default. xml.
- Site-specific configuration – conf/core-site. xml, conf/hdfs-site. xml and conf/mapred-site. xml.
How do you implement Sqoop incremental merge?
Sqoop Merge Syntax & Arguments. However, the job arguments can be entered in any order with respect to one another while the Hadoop generic arguments must precede any merge arguments. Specify the name of the record-specific class to use during the merge job. Specify the name of the jar to load the record class from.
How does Sqoop export work?
Sqoop’s export process will read a set of delimited text files from HDFS in parallel, parse them into records, and insert them as new rows in a target database table, for consumption by external applications or users. Sqoop includes some other commands which allow you to inspect the database you are working with.
How do I pass a query in sqoop?
Apache Sqoop can import the result set of the arbitrary SQL query. Rather than using the arguments –table, –columns and –where, we can use –query argument for specifying a SQL statement. Note: While importing the table via the free-form query, we have to specify the destination directory with the –target-dir argument.
What is free-form query?
Investigators search for exact character string matches by entering the query terms directly in the search criteria field on the Forensics tab. You can use single or multiple word queries. Searches for a match for one or more characters in the middle or end of a query term. …
How do I export data from hive to Oracle?
- Step 1: Sqoop import data from Oracle database to Hive table. …
- Step 2: Load the above Sqoop extracted data to a Hive table. …
- Step 3: Export a file using Hive query to be consumed by Sqoop. …
- Step 4: Load data from Hive table exported file to Oracle database table.