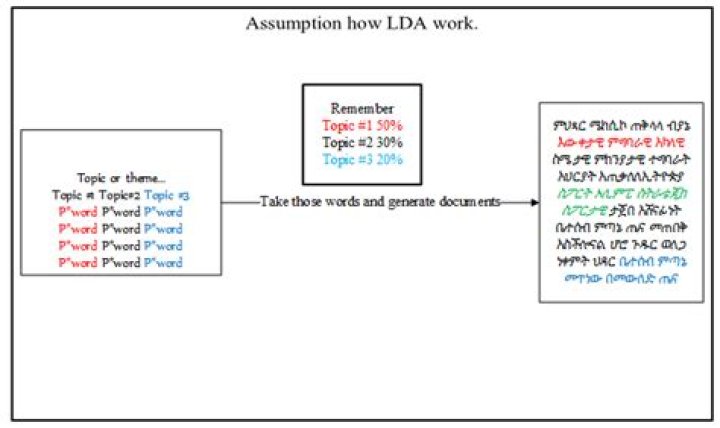
How LDA works step by step

Robert Spencer
Published Apr 09, 2026
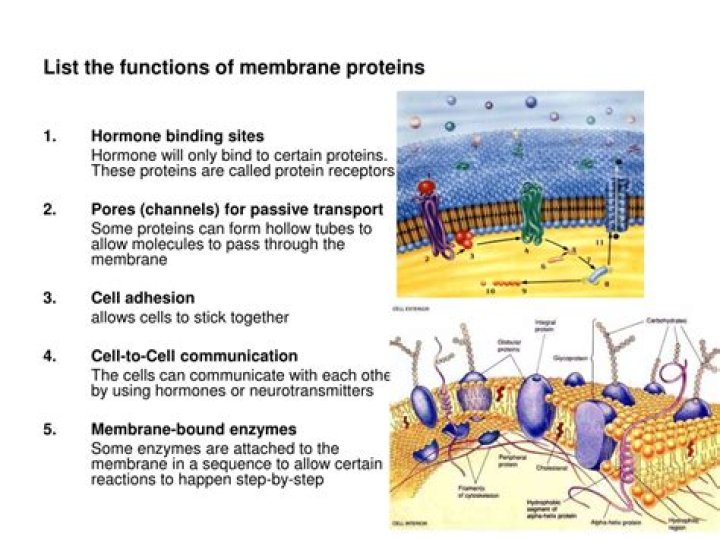
The number of words in the document are determined.A topic mixture for the document over a fixed set of topics is chosen.A topic is selected based on the document’s multinomial distribution.
How does LDA work in machine learning?
LDA makes predictions by estimating the probability that a new set of inputs belongs to each class. The class that gets the highest probability is the output class and a prediction is made.
How do you calculate LDA?
- Compute the d-dimensional mean vectors for the different classes from the dataset.
- Compute the scatter matrices (in-between-class and within-class scatter matrix).
- Compute the eigenvectors (ee1,ee2,…,eed) and corresponding eigenvalues (λλ1,λλ2,…,λλd) for the scatter matrices.
How do you build a LDA model?
- Loading Data Set. …
- Prerequisite. …
- Importing Necessary Packages. …
- Preparing Stopwords. …
- Clean up the Text. …
- Building Bigram & Trigram Models. …
- Filter out Stopwords. …
- Building Dictionary & Corpus for Topic Model.
Is LDA supervised?
Linear discriminant analysis (LDA) is one of commonly used supervised subspace learning methods. However, LDA will be powerless faced with the no-label situation.
How many documents do you need for LDA?
Model definition We have 5 documents each containing the words listed in front of them( ordered by frequency of occurrence).
How does LDA reduce dimensionality?
Linear Discriminant Analysis also works as a dimensionality reduction algorithm, it means that it reduces the number of dimension from original to C — 1 number of features where C is the number of classes. In this example, we have 3 classes and 18 features, LDA will reduce from 18 features to only 2 features.
What is a good coherence score for LDA?
Contexts in source publication achieve the highest coherence score = 0.4495 when the number of topics is 2 for LSA, for NMF the highest coherence value is 0.6433 for K = 4, and for LDA we also get number of topics is 4 with the highest coherence score which is 0.3871 (see Fig. …What is LDA topic Modelling?
Topic modeling is a type of statistical modeling for discovering the abstract “topics” that occur in a collection of documents. Latent Dirichlet Allocation (LDA) is an example of topic model and is used to classify text in a document to a particular topic.
How do you evaluate LDA results?LDA is typically evaluated by either measuring perfor- mance on some secondary task, such as document clas- sification or information retrieval, or by estimating the probability of unseen held-out documents given some training documents.
Article first time published onWhat is corpus in LDA?
A corpus is simply a set of documents. You’ll often read “training corpus” in literature and documentation, including the Spark Mllib, to indicate the set of documents used to train a model.
Where is LDA used?
Linear discriminant analysis (LDA) is used here to reduce the number of features to a more manageable number before the process of classification. Each of the new dimensions generated is a linear combination of pixel values, which form a template.
What is the goal of LDA?
The aim of LDA is to maximize the between-class variance and minimize the within-class variance, through a linear discriminant function, under the assumption that data in every class are described by a Gaussian probability density function with the same covariance.
How is LDA different from PCA?
Both LDA and PCA are linear transformation techniques: LDA is a supervised whereas PCA is unsupervised – PCA ignores class labels. … In contrast to PCA, LDA attempts to find a feature subspace that maximizes class separability (note that LD 2 would be a very bad linear discriminant in the figure above).
Why LDA is unsupervised?
LDA is unsupervised by nature, hence it does not need predefined dictionaries. This means it finds topics automatically, but you cannot control the kind of topics it finds. That’s right that LDA is an unsupervised method.
Is Knn supervised or unsupervised?
The k-nearest neighbors (KNN) algorithm is a simple, supervised machine learning algorithm that can be used to solve both classification and regression problems.
What are the advantages of dimensionality reduction?
Advantages of dimensionality reduction It reduces the time and storage space required. The removal of multicollinearity improves the interpretation of the parameters of the machine learning model. It becomes easier to visualize the data when reduced to very low dimensions such as 2D or 3D. Reduce space complexity.
Does LDA improve accuracy?
That because the feature extraction based on LDA improves the efficiency and accuracy, the two-procedure MI based strong classifier generation mechanism further enhances the precision.
Does LDA need scaling?
Linear Discriminant Analysis (LDA) finds it’s coefficients using the variation between the classes (check this), so the scaling doesn’t matter either.
Can LDA be used for regression?
Linear discriminant analysis and linear regression are both supervised learning techniques. But, the first one is related to classification problems i.e. the target attribute is categorical; the second one is used for regression problems i.e. the target attribute is continuous (numeric).
What are the limitations of LDA?
- Fixed K (the number of topics is fixed and must be known ahead of time)
- Uncorrelated topics (Dirichlet topic distribution cannot capture correlations)
- Non-hierarchical (in data-limited regimes hierarchical models allow sharing of data)
- Static (no evolution of topics over time)
What is topic Modelling in NLP?
Topic modelling refers to the task of identifying topics that best describes a set of documents. These topics will only emerge during the topic modelling process (therefore called latent). And one popular topic modelling technique is known as Latent Dirichlet Allocation (LDA).
Is Topic Modelling supervised or unsupervised?
Topic modeling is an ‘unsupervised’ machine learning technique, in other words, one that doesn’t require training. Topic classification is a ‘supervised’ machine learning technique, one that needs training before being able to automatically analyze texts.
Is LDA better than PCA?
PCA performs better in case where number of samples per class is less. Whereas LDA works better with large dataset having multiple classes; class separability is an important factor while reducing dimensionality.
Is LDA stochastic?
(2010) introduced Online LDA, a stochastic gradient optimization algorithm for topic modeling.
Is Latent Dirichlet Allocation clustering?
Strictly speaking, Latent Dirichlet Allocation (LDA) is not a clustering algorithm. This is because clustering algorithms produce one grouping per item being clustered, whereas LDA produces a distribution of groupings over the items being clustered.
What is LDA mallet?
What is LDA Mallet Model? Mallet, an open source toolkit, was written by Andrew McCullum. It is basically a Java based package which is used for NLP, document classification, clustering, topic modeling, and many other machine learning applications to text.
What is coherence LDA?
Topic Coherence measures score a single topic by measuring the degree of semantic similarity between high scoring words in the topic. These measurements help distinguish between topics that are semantically interpretable topics and topics that are artifacts of statistical inference.
What is the optimal number of topics for LDA in Python?
How to find the optimal number of topics for LDA? The approach to finding the optimal number of topics is to build many LDA models with different values of a number of topics (k) and pick the one that gives the highest coherence value.
What is perplexity in topic modeling?
Perplexity is a statistical measure of how well a probability model predicts a sample. As applied to LDA, for a given value of , you estimate the LDA model. Then given the theoretical word distributions represented by the topics, compare that to the actual topic mixtures, or distribution of words in your documents.
What is C_V coherence?
It is called ‘C_v topic coherence’. It measures how often the topic words appear together in the corpus. Of course, the trick is how to define ‘together’. Gensim supports several topic coherence measures including C_v.