How do I connect to HBase

Sophia Edwards
Published Feb 22, 2026
Provide Hadoop Identity. … Provide HBase Identity. … The path to the core-site. … Select Authentication method. … In the HBase Namespace and Target table, specify the table name to which you want to connect and namespace in which it is created (if different than the default namespace).
How do I start HBase?
We can start HBase by using start-hbase.sh script provided in the bin folder of HBase. For that, open HBase Home Folder and run HBase start script as shown below. If everything goes well, when you try to run HBase start script, it will prompt you a message saying that HBase has started.
How do I view databases in HBase?
- You have a method called listTables() in the class HBaseAdmin to get the list of all the tables in HBase. This method returns an array of HTableDescriptor objects. …
- You can get the length of the HTableDescriptor[] array using the length variable of the HTableDescriptor class.
How do I access HBase from Java?
- Step 1: Instantiate the Configuration Class. Configuration class adds HBase configuration files to its object. …
- Step 2: Instantiate the HTable Class. …
- Step 3: Instantiate the Get Class. …
- Step 4: Read the Data. …
- Step 5: Get the Result. …
- Step 6: Reading Values from the Result Instance.
What type of database is HBase?
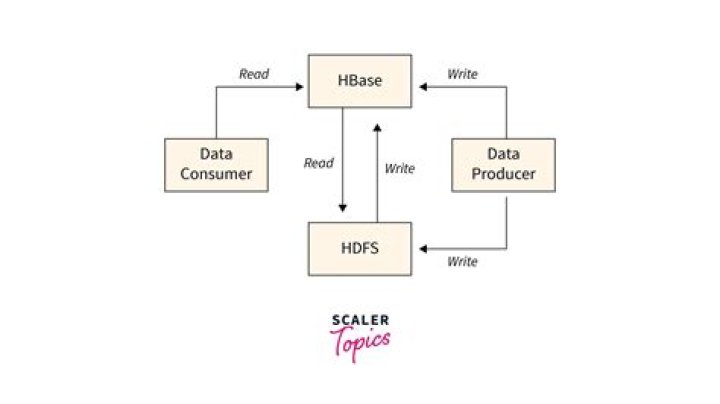
HBase is a column-oriented non-relational database management system that runs on top of Hadoop Distributed File System (HDFS). HBase provides a fault-tolerant way of storing sparse data sets, which are common in many big data use cases.
How do I create a HBase database?
- Step 1:Instantiate the Configuration Class. …
- Step 2:Instantiate the HTable Class. …
- Step 3: Instantiate the PutClass. …
- Step 4: Insert Data. …
- Step 5: Save the Data in Table. …
- Step 6: Close the HTable Instance.
Is HBase a NoSQL database?
Apache HBase is a column-oriented, NoSQL database built on top of Hadoop (HDFS, to be exact). It is an open source implementation of Google’s Bigtable paper. HBase is a top-level Apache project and just released its 1.0 release after many years of development. Data in HBase is broken into tables.
How do I open HBase in cloudera?
- Step 1: Configure a Repository.
- Step 2: Install JDK.
- Step 3: Install Cloudera Manager Server.
- Step 4: Install Databases. Install and Configure MariaDB. Install and Configure MySQL. Install and Configure PostgreSQL. …
- Step 5: Set up the Cloudera Manager Database.
- Step 6: Install CDH and Other Software.
- Step 7: Set Up a Cluster.
Where is HBase site xml located?
In all cases of hbase the /etc/hbase/conf/hbase-site. xml file is always read. The /usr/lib/hbase/conf/hbase-site. xml is a symlink to /etc/hbase/conf/hbase-site.
What is HBase site XML?hbase-site.xml. The path to the hbase-site. xml file that contains all the information required to connect to target HBase database (such as zookeeper quorum, port, parent znode). This file s copied from the target cluster and placed in some local directory.
Article first time published onWhat is Phoenix Database?
Apache Phoenix is an open source, massively parallel, relational database engine supporting OLTP for Hadoop using Apache HBase as its backing store.
What is the difference between GET and scan in HBase?
When you compare a partial key scan and a get, remember that the row key you use for Get can be a much longer string than the partial key you use for the scan. In that case, for the Get, HBase has to do a deterministic lookup to ascertain the exact location of the row key that it needs to match and fetch it.
How do I find my HBase version?
1 Answer. hbase version command in command line interface gives the version of hbase that is being in use.
How do I know if HBase is running?
- Use the jps command to ensure that HBase is not running.
- Kill HMaster, HRegionServer, and HQuorumPeer processes, if they are running.
- Start the cluster by running the start-hbase.sh command on node-1.
How do I access HBase table from hive?
To access HBase data from Hive You can then reference inputTable in Hive statements to query and modify data stored in the HBase cluster. set hbase. zookeeper. quorum=ec2-107-21-163-157.compute-1.amazonaws.com; create external table inputTable (key string, value string) stored by ‘org.
Where is HBase used?
Apache HBase is used to have random, real-time read/write access to Big Data. It hosts very large tables on top of clusters of commodity hardware. Apache HBase is a non-relational database modeled after Google’s Bigtable. Bigtable acts up on Google File System, likewise Apache HBase works on top of Hadoop and HDFS.
How is data stored in HBase?
There are no data types in HBase; data is stored as byte arrays in the cells of HBase table. The content or the value in cell is versioned by the timestamp when the value is stored in the cell. So each cell of an HBase table may contain multiple versions of data.
Who owns HBase?
HBase is an open-source non-relational distributed database modeled after Google’s Bigtable and written in Java. It is developed as part of Apache Software Foundation’s Apache Hadoop project and runs on top of HDFS (Hadoop Distributed File System) or Alluxio, providing Bigtable-like capabilities for Hadoop.
How HBase is different from MongoDB?
MongoDB is an open-source non-relational database. All related information is stored together to quickly access the data. HBase, on the other hand, is written in Java and works on the Hadoop framework. It uses a key-value pair to access random patterns generated.
Who is using HBase?
CompanyWebsiteCompany SizeQA Limitedqa.com1000-5000The American Red Crossredcross.org>10000Zendesk Inczendesk.com1000-5000Lorven Technologieslorventech.com50-200
How is HBase different from other NoSQL model?
Apache HBase is a NoSQL key/value store which runs on top of HDFS. Unlike Hive, HBase operations run in real-time on its database rather than MapReduce jobs. … HBase enjoys Hadoop’s infrastructure and scales horizontally using off the shelf servers. HBase works by storing data as key/value.
What is HBase version?
A version is a timestamp values is written alongside each value. By default, the timestamp values represent the time on the RegionServer when the data was written, but you can change the default HBase setting and specify a different timestamp value when you put data into the cell.
How many masters are possible in HBase?
How many masters are possible in hbase? In Hbase, a cluster consists of one Master and three or more Region Servers.
What is HBase discuss various HBase data model and applications?
HBase is a column-oriented database that’s an open-source implementation of Google’s Big Table storage architecture. It can manage structured and semi-structured data and has some built-in features such as scalability, versioning, compression and garbage collection.
Which file system is used by Hbase to store its data?
Hadoop Distributed File System (HDFS), the commonly known file system of Hadoop and Hbase (Hadoop’s database) are the most topical and advanced data storage and management systems available in the market.
Where is hive site XML in cloudera?
If the components are manually installed using Cloudera parcels and if you want to override any configuration property, use the corresponding configuration file under /etc/<component>/conf/ . There used to be a file called hive-default. xml.
What is the function of Hbase ENV SH Apache Hbase configuration file?
hbase-env.sh provides a handy mechanism to do this. HBase uses the Secure Shell (ssh) command and utilities extensively to communicate between cluster nodes. Each server in the cluster must be running ssh so that the Hadoop and HBase daemons can be managed.
What is HBase cloudera?
HBase is a high-performance, distributed data store that integrates with Cloudera’s platform to deliver a secure and easy-to-manage NoSQL database.
What is snapshot in HBase?
HBase snapshot support enables you to take a snapshot of a table without much impact on RegionServers, because snapshot, clone, and restore operations do not involve data copying. In addition, exporting a snapshot to another cluster has no impact on RegionServers.
How do I add a column family to an existing HBase table?
Simply press the “+” button in the “Alter table” page and add your new column family with all settings you need.
How install HBase on Windows?
- Start a Cygwin terminal, if you haven’t already.
- Change directory to HBase installation using CD /usr/local/hbase-<version>, preferably using auto-completion.
- Start HBase using the command ./bin/start-hbase.sh. …
- Next we start the HBase shell using the command ./bin/hbase shell.